MXNet的数据格式设计及实现。
深度学习通常使用的数据量很大,这些数据往往不能全部载入到内存/显存。一般是把数据以一定格式保存到硬盘,在需要使用时再读到内存/显存。MxNet的输入载入以及数据格式都是自定义的。数据载入要满足以下要求:
- 并行(分布式)打包数据。
- 数据载入快,在线数据增强。
- 可以在分布式设置中快速读数据任意部分。
设计概要
Data IO可以分为数据准备和数据载入两个阶段。数据准备阶段是把数据打包为特定格式,一般对时间没有严格要求。输入载入发生在训练阶段,对时间有严格要求。
数据准备
- 数据准备是把训练数据打包为一个文件。
- 打包过程可以并行。
- 可以方便的读取文件任何位置。在分布式机器学习中,这一点非常重要。打包数据的物理文件个数和逻辑文件个数可以不同;例如把1000张图片打包为4个文件,每个包含250张。如果使用10台机器训练,每台机器应该用100张图片,这时有些机器需要读不同的物理文件。
数据载入
把数据载入到RAM的速度越快越好。下面有几个遵守的准则:
- 连续读:连贯读硬盘同一个位置,读取速度更快。
- 减少读的字节:例如,使用压缩格式存储文件。
- 载入和训练使用不同thread:避免计算瓶颈。
- 保存到RAM:可以选择是否全部读到RAM。
数据格式
数据以二进制格式保存,格式如下: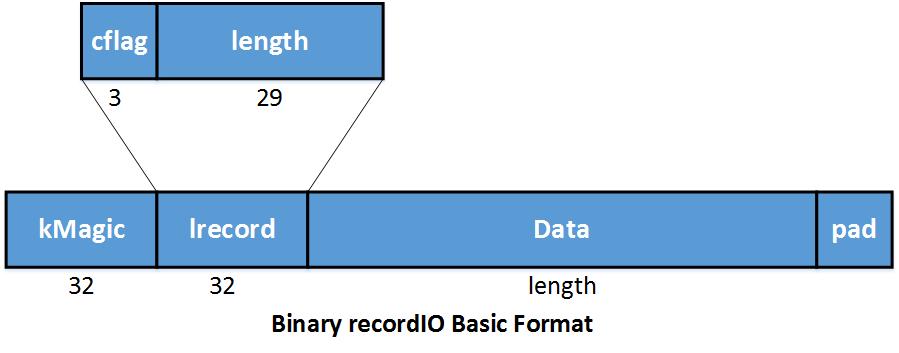
其中kMagic是幻数,标识一条记录的开始。Lrrecord记录了数据长度和连续标识cflag:
- cflag == 0: 完整记录
- cflag == 1: 多条记录的起始部分
- cflag == 2: 多条记录的中间部分
- cflag == 3: 多条记录的结束部分
Data存储数据。pad用来填充,4字节对齐。
把多个文件打包文一个文件后,避免了随机从硬盘读数据。每个record长度可以变化,可以使用压缩格式保存数据。例如ImageNet_1k数据集,使用3256256的raw rgb存储占用空间超过200G;使用JPEG压缩后,占用空间大约35G。
一个二进制recordIO示例:
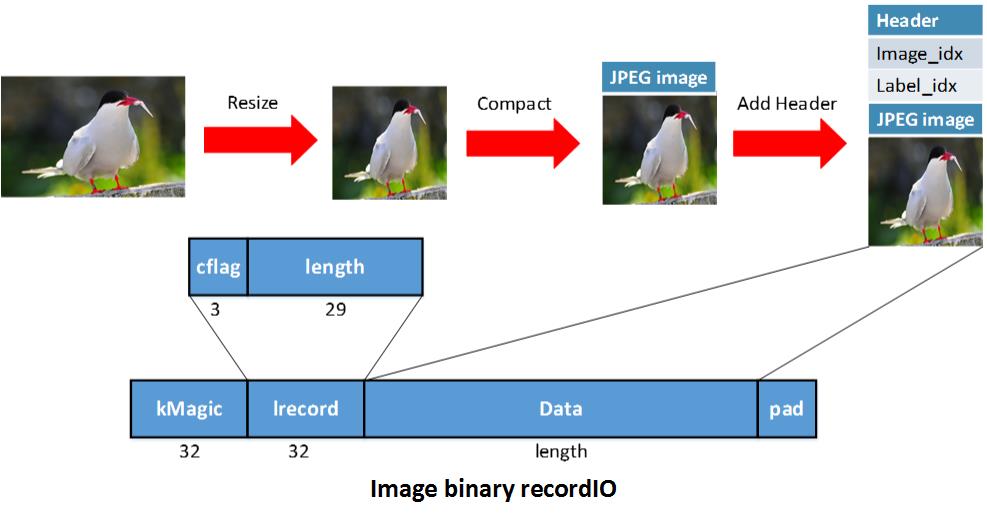
随机读取数据任意位置
不管打包的物理文件有多少个,逻辑上可以划分为任意多个。通过幻数可以快速定位到起始结束位置,通过InputSplit可以实现这个功能。
代码
Data io,主要是input和ouput。
input主要是把图片标签打包,output是把打包的数据抽出来。input实现主要在RecordIOWriter,output实现主要在RecordIOSplitter。下面是各个类的关系:
各个类
ImageRecordIO是struct,对应recordIOInputSplit用来从输入的文件提取单条记录;最终泛化为两个类LineSplitter和RecordSplitter,前者通过行来分割文件,后者每次提取一个Record。Chunk用来存储读取的数据,一次从硬盘读取固定大小(例如16M)数据,存储在里面。Blob存储一次需要使用的数据(只是存储指针,数据在Chunk中)。FileSystem,不同文件系统读写不一样,封装了统一的读取接口。Stream流式读取接口,结合Serializable来序列化数据。
MXNet打包图片时,用到了im2rec.cc文件,一次为例,来看一下具体过程。flist->NextRecord(&line)调用过程:InputSplitBase::NextRecord(Blob *out_rec)–>LineSplitter::ExtractNextRecord(Blob *out_rec, Chunk *chunk)Chunk中保存了‘一批’数据在内存,每次读取先从Chunk读取,之后再在Chunk中找起始和结束位置,分割每条数据。Blob只是pointer和size,没有保存实际数据。实际数据在Chunk中;因此在使用数据前,Chunk不能修改或释放。
上面读取了具体的文件位置和标签,下面通过位置读取文件,和标签一起,打包到文件。
文件可能存放在不同文件系统,但可以通过uri确定。文件系统可以可以通过协议确定,例如”file://“表示存储在本地,”hdfs://“表示存储在hdfs等。文件系统抽象为FileSystem,通过单例模式得到在用的文件系统的实例。
读取图片二进制文件,再转换为Mat结构,做数据增强,在编码为二进制压缩形式,保存到record中。